Erstellen von Clustered- und Non-Clustered-Indizes in SQL Server
Clustered-Index:
Eine Clusterliste ist ein bestimmter Indextyp, der die physische Speicherung von Datensätzen in der Tabelle neu ordnet. In SQL Server werden Indizes verwendet, um Datenbankoperationen zu beschleunigen, was zu einer hohen Leistung führt. Die Tabelle kann daher nur einen Clustered-Index haben, was normalerweise für den Primärschlüssel erfolgt. Die Blattknoten eines Clustered-Index enthalten “Datenseiten”. Eine Tabelle kann nur einen Clustered-Index besitzen.
Lassen Sie uns einen Clustered-Index erstellen, um ein besseres Verständnis zu erhalten. Zunächst müssen wir eine Datenbank erstellen.
Datenbankerstellung
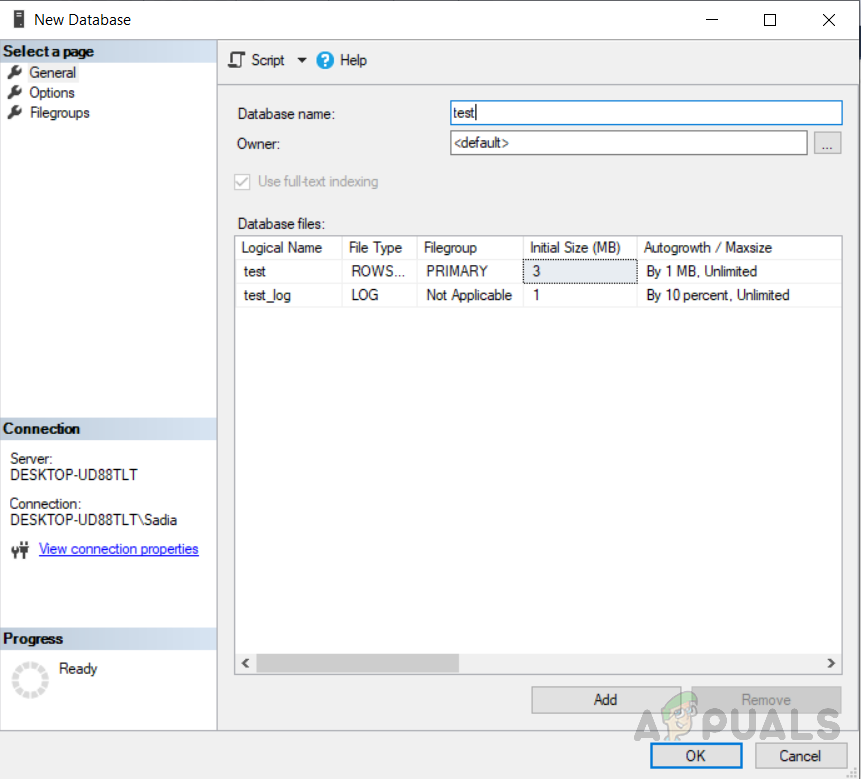
Um eine Datenbank zu erstellen. Klicken Sie mit der rechten Maustaste auf “Datenbanken” im Objekt-Explorer und wählen Sie “Neue Datenbank” Möglichkeit. Geben Sie den Namen der Datenbank ein und klicken Sie auf OK. Die Datenbank wurde wie in der folgenden Abbildung gezeigt erstellt.
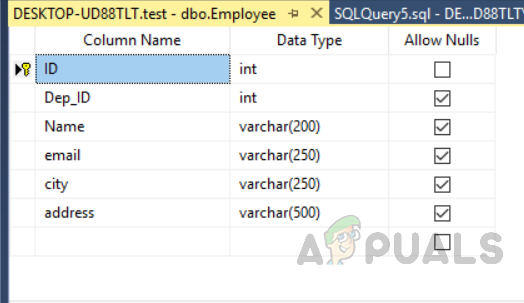
Jetzt erstellen wir eine Tabelle mit dem Namen “Mitarbeiter” mit dem Primärschlüssel mithilfe der Entwurfsansicht. In der Abbildung unten sehen wir, dass wir hauptsächlich dem Feld mit dem Namen “ID” zugewiesen haben und keinen Index für die Tabelle erstellt haben.
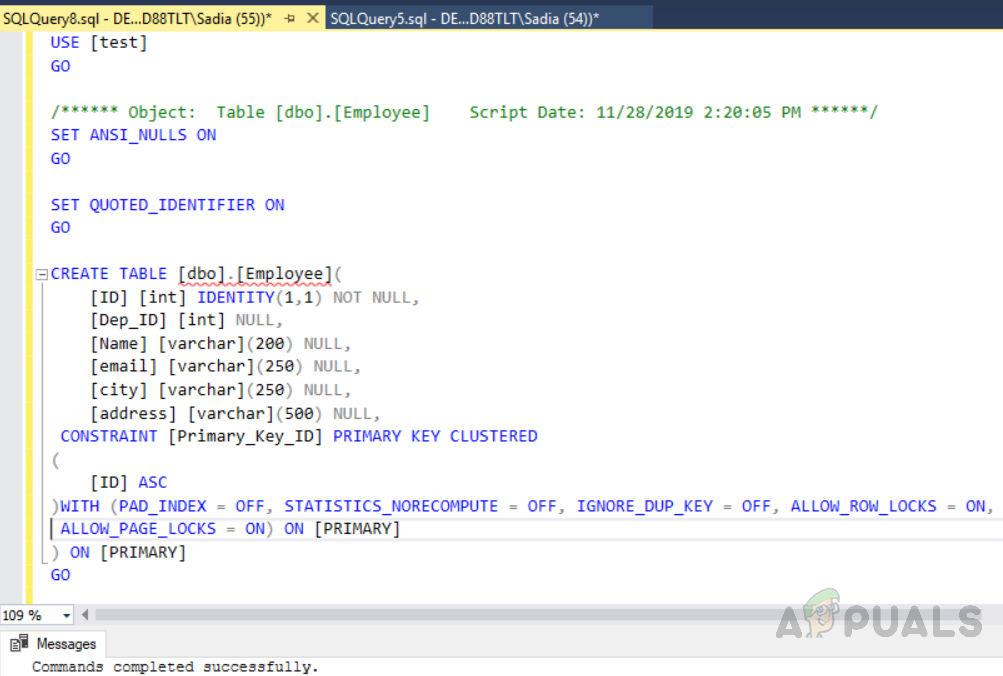
Sie können auch eine Tabelle erstellen, indem Sie den folgenden Code ausführen.
USE [test] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Employee]( [ID] [int] IDENTITY(1,1) NOT NULL, [Dep_ID] [int] NULL, [Name] [varchar](200) NULL, [email] [varchar](250) NULL, [city] [varchar](250) NULL, [address] [varchar](500) NULL, CONSTRAINT [Primary_Key_ID] PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO
Die Ausgabe wird wie folgt sein.
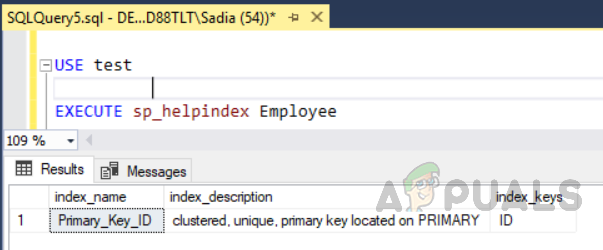
Der obige Code hat eine Tabelle mit dem Namen erstellt “Mitarbeiter” mit einem ID-Feld eine eindeutige Kennung als Primärschlüssel. In dieser Tabelle wird nun aufgrund von Primärschlüsseleinschränkungen automatisch ein Clustered-Index für die Spalten-ID erstellt. Wenn Sie alle Indizes einer Tabelle anzeigen möchten, führen Sie die gespeicherte Prozedur aus “Sp_helpindex”. Führen Sie den folgenden Code aus, um alle Indizes für eine Tabelle mit dem Namen anzuzeigen “Mitarbeiter”. Diese Speicherprozedur verwendet einen Tabellennamen als Eingabeparameter.
USE test EXECUTE sp_helpindex Employee
Die Ausgabe wird wie folgt sein.
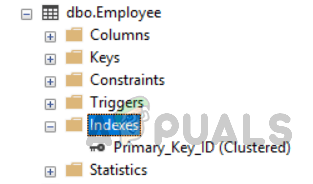
Eine andere Möglichkeit zum Anzeigen von Tabellenindizes ist das Wechseln zu “Tabellen” im Objekt-Explorer. Wählen Sie die Tabelle aus und geben Sie sie aus. Im Indexordner sehen Sie alle Indizes, die für diese bestimmte Tabelle relevant sind (siehe Abbildung unten).
Da dies der Clustered-Index ist, ist die logische und physische Reihenfolge des Index identisch. Das heißt, wenn ein Datensatz eine ID von 3 hat, wird er in der dritten Zeile der Tabelle gespeichert. Wenn der fünfte Datensatz eine ID von 6 hat, wird er ebenfalls in der 5 gespeichertth Position der Tabelle. Um die Reihenfolge der Datensätze zu verstehen, müssen Sie das folgende Skript ausführen.
USE [test] GO SET IDENTITY_INSERT [dbo].[Employee] ON INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (8, 6, N'Humbaerto Acevedo', N'humbaerto.acevedo@gmail.com', N'SAINT PAUL', N'895 E 7th St Saint Paul Mn 551063852') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (9, 6, N'Humbaerto Acevedo', N'humbaerto.acevedo@gmail.com', N'SAINT PAUL', N'895 E 7th St Saint Paul Mn 551063852') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (10, 7, N'Pilar Ackaerman', N'pilar.ackaerman@gmail.com', N'ATLANTA', N'5813 Eastern Ave Hyattsville Md 207822201') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (11, 1, N'Aaaronboy Gutierrez', N'aronboy.gutierrez@gmail.com', N'HILLSBORO', N'5840 Ne Cornell Rd Hillsboro Or 97124') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (12, 2, N'Aabdi Maghsoudi', N'abdi_maghsoudi@gmail.com', N'BRENTWOOD', N'987400 Nebraska Medical Center Omaha Ne 681987400') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (13, 3, N'Aabharana, Sahni', N'abharana.sahni@gmail.com', N'HYATTSVILLE', N'2 Barlo Circle Suite A Dillsburg Pa 170191') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (14, 3, N'Aabharana, Sahni', N'abharana.sahni@gmail.com', N'HYATTSVILLE', N'2 Barlo Circle Suite A Dillsburg Pa 170191') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (1, 1, N'Aaaronboy Gutierrez', N'aronboy.gutierrez@gmail.com', N'HILLSBORO', N'5840 Ne Cornell Rd Hillsboro Or 97124') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (2, 2, N'Aabdi Maghsoudi', N'abdi_maghsoudi@gmail.com', N'BRENTWOOD', N'987400 Nebraska Medical Center Omaha Ne 681987400') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (3, 3, N'Aabharana, Sahni', N'abharana.sahni@gmail.com', N'HYATTSVILLE', N'2 Barlo Circle Suite A Dillsburg Pa 170191') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (4, 3, N'Aabharana, Sahni', N'abharana.sahni@gmail.com', N'HYATTSVILLE', N'2 Barlo Circle Suite A Dillsburg Pa 170191') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (5, 4, N'Aabish Mughal', N'abish_mughal@gmail.com', N'OMAHA', N'2975 Crouse Lane Burlington Nc 272150000') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (6, 5, N'Aabram Howell', N'aronboy.gutierrez@gmail.com', N'DILLSBURG', N'868 York Ave Atlanta Ga 303102750') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (7, 5, N'Aabram Howell', N'aronboy.gutierrez@gmail.com', N'DILLSBURG', N'868 York Ave Atlanta Ga 303102750') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (15, 4, N'Aabish Mughal', N'abish_mughal@gmail.com', N'OMAHA', N'2975 Crouse Lane Burlington Nc 272150000') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (16, 5, N'Aabram Howell', N'aronboy.gutierrez@gmail.com', N'DILLSBURG', N'868 York Ave Atlanta Ga 303102750') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (17, 5, N'Aabram Howell', N'aronboy.gutierrez@gmail.com', N'DILLSBURG', N'868 York Ave Atlanta Ga 303102750') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (18, 6, N'Humbaerto Acevedo', N'humbaerto.acevedo@gmail.com', N'SAINT PAUL', N'895 E 7th St Saint Paul Mn 551063852') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (19, 6, N'Humbaerto Acevedo', N'humbaerto.acevedo@gmail.com', N'SAINT PAUL', N'895 E 7th St Saint Paul Mn 551063852') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (20, 7, N'Pilar Ackaerman', N'pilar.ackaerman@gmail.com', N'ATLANTA', N'5813 Eastern Ave Hyattsville Md 207822201') SET IDENTITY_INSERT [dbo].[Employee] OFF
Obwohl Datensätze in einer zufälligen Reihenfolge von Werten in der Spalte „Id“ gespeichert sind. Aber aufgrund des Clustered-Index für die ID-Spalte. Datensätze werden physisch in aufsteigender Reihenfolge der Werte in der ID-Spalte gespeichert. Um dies zu überprüfen, müssen wir den folgenden Code ausführen.
Select * from test.dbo.Employee
Die Ausgabe wird wie folgt sein.
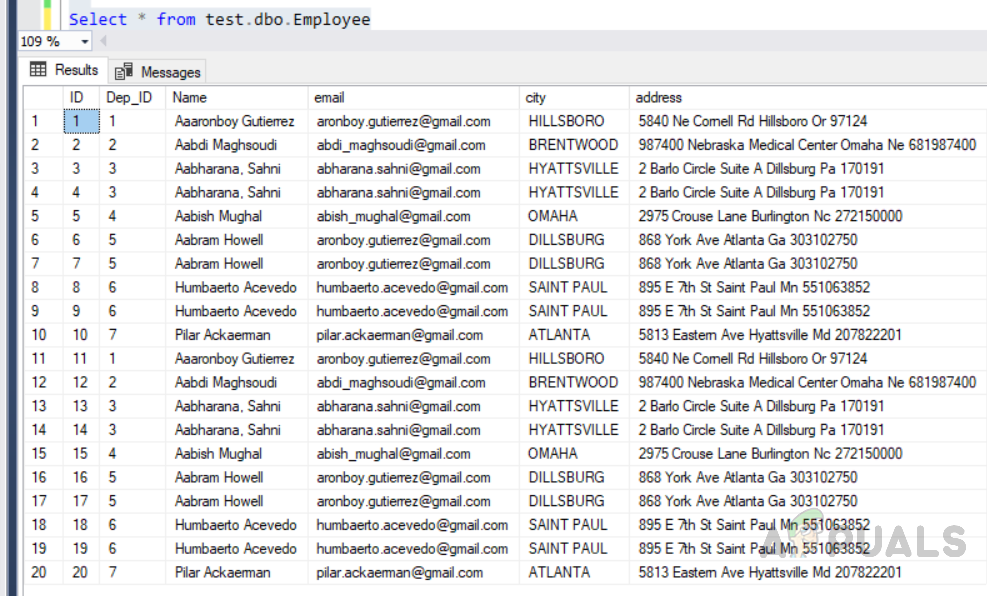
Wir können in der obigen Abbildung sehen, dass Datensätze in aufsteigender Reihenfolge der Werte in der ID-Spalte abgerufen wurden.
Angepasster Clustered-Index
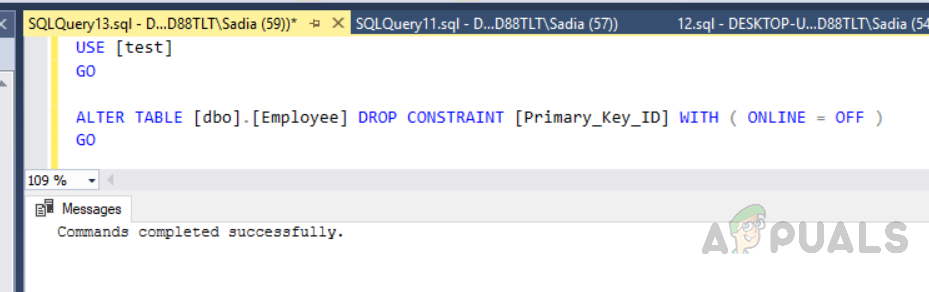
Sie können auch einen benutzerdefinierten Clustered-Index erstellen. Da wir nur einen Clustered-Index erstellen können, müssen wir den vorherigen löschen. Führen Sie den folgenden Code aus, um den Index zu löschen.
USE [test] GO ALTER TABLE [dbo].[Employee] DROP CONSTRAINT [Primary_Key_ID] WITH ( ONLINE = OFF ) GO
Die Ausgabe wird wie folgt sein.
Um nun den Index zu erstellen, führen Sie den folgenden Code in einem Abfragefenster aus. Dieser Index wurde für mehr als eine Spalte erstellt und wird daher als zusammengesetzter Index bezeichnet.
USE [test] GO CREATE CLUSTERED INDEX [ClusteredIndex-20191128-173307] ON [dbo].[Employee] ( [ID] ASC, [Dep_ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO
Die Ausgabe wird wie folgt sein
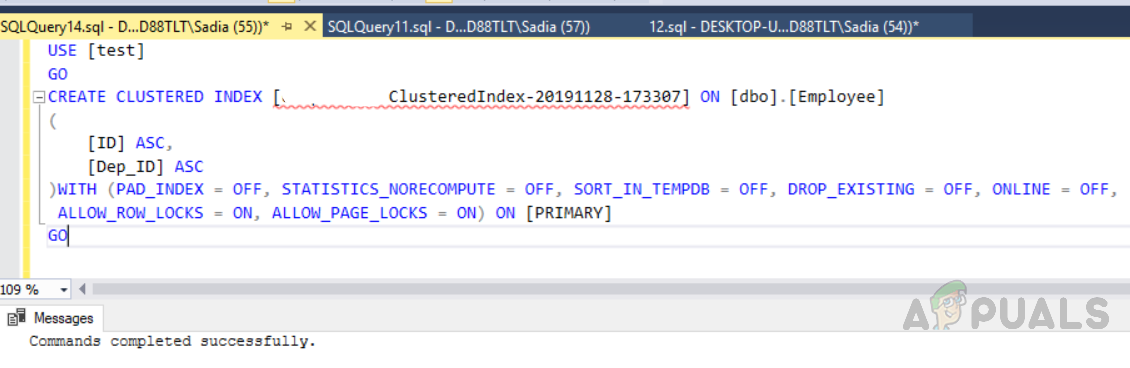
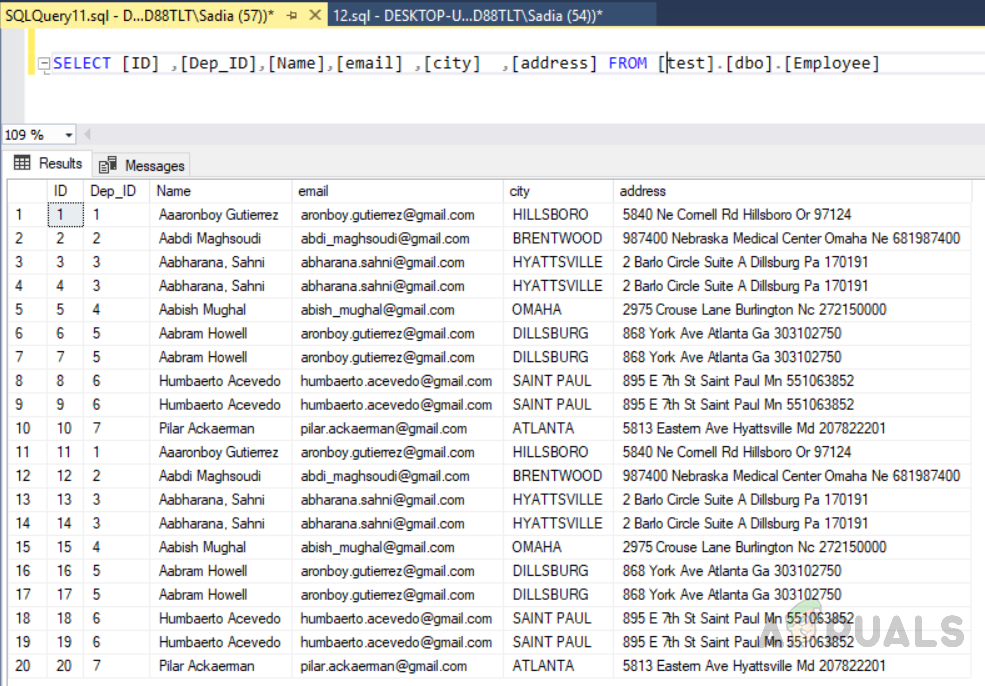
Wir haben einen benutzerdefinierten Clustered-Index für ID und Dep_ID erstellt. Dadurch werden die Zeilen nach ID und dann nach Dep_Id sortiert. Um dies anzuzeigen, führen Sie den folgenden Code aus. Das Ergebnis ist eine aufsteigende Reihenfolge der ID und dann By Dep_id.
SELECT [ID] ,[Dep_ID],[Name],[email] ,[city] ,[address] FROM [test].[dbo].[Employee]
Die Ausgabe wird wie folgt sein.
Nicht gruppierter Index:
Ein nicht gruppierter Index ist ein bestimmter Indextyp, bei dem die logische Reihenfolge des Index nicht mit der auf der Festplatte gespeicherten physischen Reihenfolge der Zeilen übereinstimmt. Der Blattknoten des nicht gruppierten Index enthält keine Datenseiten, sondern Informationen zu Indexzeilen. Eine Tabelle kann bis zu 249 Indizes besitzen. Standardmäßig erstellt eine Einschränkung für eindeutige Schlüssel einen nicht gruppierten Index. Beim Lesevorgang sind nicht gruppierte Indizes langsamer als gruppierte Indizes. Ein nicht gruppierter Index enthält eine Kopie der Daten aus den indizierten Spalten, die in der richtigen Reihenfolge gehalten werden, sowie Verweise auf die tatsächlichen Datenzeilen. Zeiger auf die Clusterliste, falls vorhanden. Daher ist es eine gute Idee, nur die Spalten auszuwählen, die im Index verwendet werden, anstatt * zu verwenden. Auf diese Weise können Daten direkt aus dem doppelten Index abgerufen werden. Ein ansonsten gruppierter Index wird auch verwendet, um verbleibende Spalten auszuwählen, wenn er erstellt wird.
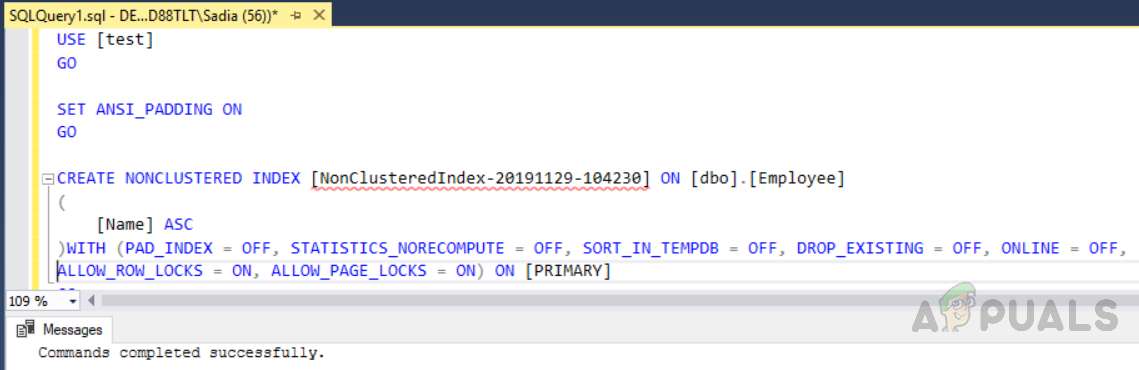
Die Syntax zum Erstellen eines nicht gruppierten Index ähnelt dem gruppierten Index. Allerdings das Schlüsselwort “NICHT CLUSTERED” wird anstelle von verwendet “CLUSTERED” im Fall des nicht gruppierten Index. Führen Sie das folgende Skript aus, um einen nicht gruppierten Index zu erstellen.
USE [test] GO SET ANSI_PADDING ON GO CREATE NONCLUSTERED INDEX [NonClusteredIndex-20191129-104230] ON [dbo].[Employee] ( [Name] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO
Die Ausgabe wird wie folgt sein.
Die Tabellendatensätze werden nach einem Clustered-Index sortiert, wenn er erstellt wurde. Dieser neue nicht gruppierte Index sortiert die Tabelle gemäß ihrer Definition und wird in einer separaten physischen Adresse gespeichert. Das obige Skript erstellt den Index für die Spalte “NAME” der Employee-Tabelle. Dieser Index sortiert die Tabelle in aufsteigender Reihenfolge der Spalte „Name“. Die Tabellendaten und der Index werden, wie bereits erwähnt, an verschiedenen Orten gespeichert. Führen Sie nun das folgende Skript aus, um die Auswirkungen eines neuen nicht gruppierten Index anzuzeigen.
select Name from Employee
Die Ausgabe wird wie folgt sein.
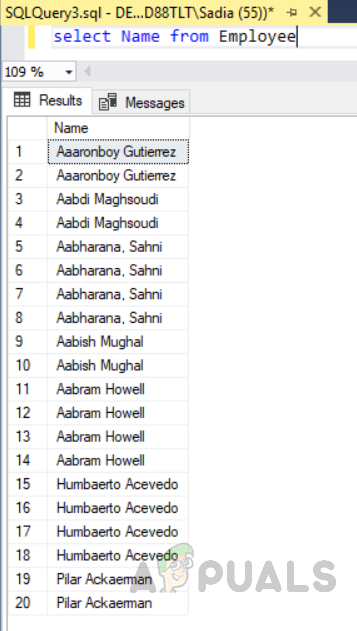
In der obigen Abbildung sehen wir, dass die Spalte Name der Tabelle Employee in aufsteigender Reihenfolge der Namensspalte angezeigt wurde, obwohl wir die Klausel „Order by ASC“ mit der select-Klausel nicht erwähnt haben. Dies liegt an dem nicht gruppierten Index für die Spalte “Name”, die in der Employee-Tabelle erstellt wurde. Wenn nun eine Abfrage geschrieben wird, um den Namen, die E-Mail-Adresse, den Ort und die Adresse der jeweiligen Person abzurufen. Die Datenbank sucht zuerst nach diesem bestimmten Namen im Index und ruft dann relevante Daten ab, wodurch die Abrufzeit für Abfragen verkürzt wird, insbesondere wenn die Daten sehr groß sind.
select Name, email, city, address from Employee where name="Aaaronboy Gutierrez"
Fazit
Aus der obigen Diskussion haben wir erfahren, dass der Clustered-Index nur einer sein kann, während der Nicht-Clustered-Index viele sein kann. Der Clustered-Index ist schneller als der Nicht-Clustered-Index. Der Clustered-Index belegt keinen zusätzlichen Speicherplatz, während der Nicht-Clustered-Index zusätzlichen Speicher benötigt, um sie zu speichern. Wenn wir eine Primärschlüsseleinschränkung auf die Tabelle anwenden, wird automatisch ein Clustered-Index erstellt. Wenn wir eine eindeutige Schlüsselbeschränkung auf eine Spalte anwenden, wird automatisch ein nicht gruppierter Index darauf erstellt. Nicht gruppierter Index ist schneller als gruppierter Index für Einfüge- und Aktualisierungsvorgänge. Eine Tabelle darf keinen nicht gruppierten Index haben.