
Wie entferne ich doppelte Zeilen aus einer SQL Server-Tabelle?
Beispielsweise könnten wir diese Art von Daten auch beim Importieren von Zwischentabellen abrufen und möchten redundante Zeilen löschen, bevor wir sie tatsächlich zu den Produktionstabellen hinzufügen. Darüber hinaus sollten wir die Aussicht auf das Duplizieren von Zeilen nicht verlassen, da doppelte Informationen die mehrfache Bearbeitung von Anforderungen, falsche Berichtsergebnisse und mehr ermöglichen. Wenn die Spalte jedoch bereits doppelte Zeilen enthält, müssen wir bestimmte Methoden befolgen, um die doppelten Daten zu bereinigen. Schauen wir uns in diesem Artikel einige Möglichkeiten an, um Datenverdopplungen zu entfernen.
Wie entferne ich doppelte Zeilen aus einer SQL Server-Tabelle?
In SQL Server gibt es eine Reihe von Möglichkeiten, doppelte Datensätze in einer Tabelle zu verarbeiten, basierend auf bestimmten Umständen wie:
Entfernen doppelter Zeilen aus einer eindeutigen Index-SQL Server-Tabelle
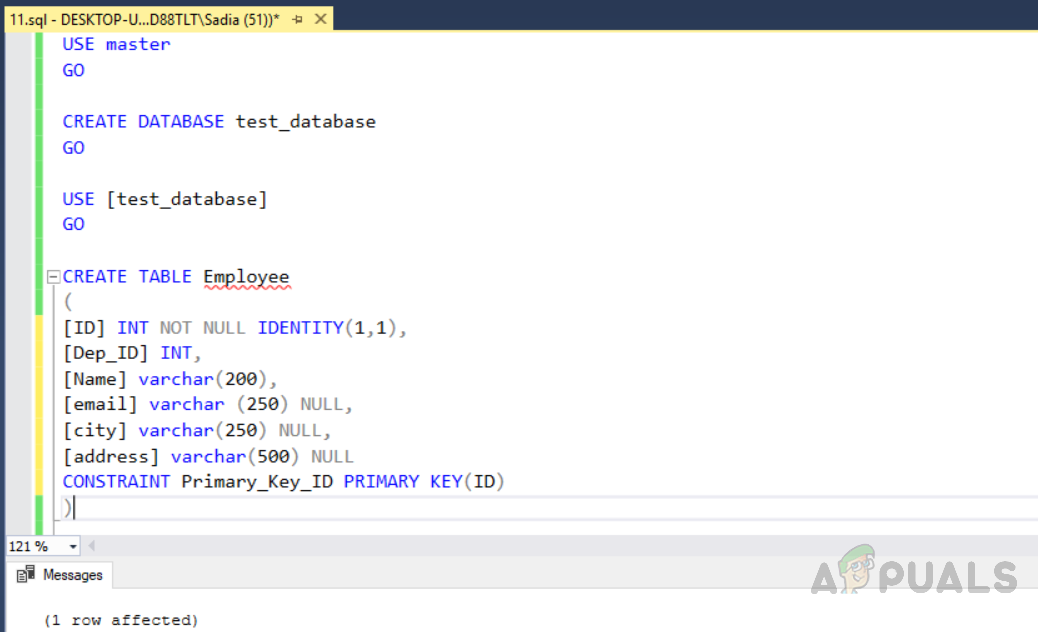
Sie können den Index verwenden, um die doppelten Daten in eindeutigen Indextabellen zu klassifizieren und dann die doppelten Datensätze zu löschen. Zuerst müssen wir eine Datenbank mit dem Namen “test_database” erstellen und dann eine Tabelle “Employee” mit einem eindeutigen Index unter Verwendung des unten angegebenen Codes erstellen.
USE master GO CREATE DATABASE test_database GO USE [test_database] GO CREATE TABLE Employee ( [ID] INT NOT NULL IDENTITY(1,1), [Dep_ID] INT, [Name] varchar(200), [email] varchar (250) NULL, [city] varchar(250) NULL, [address] varchar(500) NULL CONSTRAINT Primary_Key_ID PRIMARY KEY(ID) )
Die Ausgabe erfolgt wie folgt.
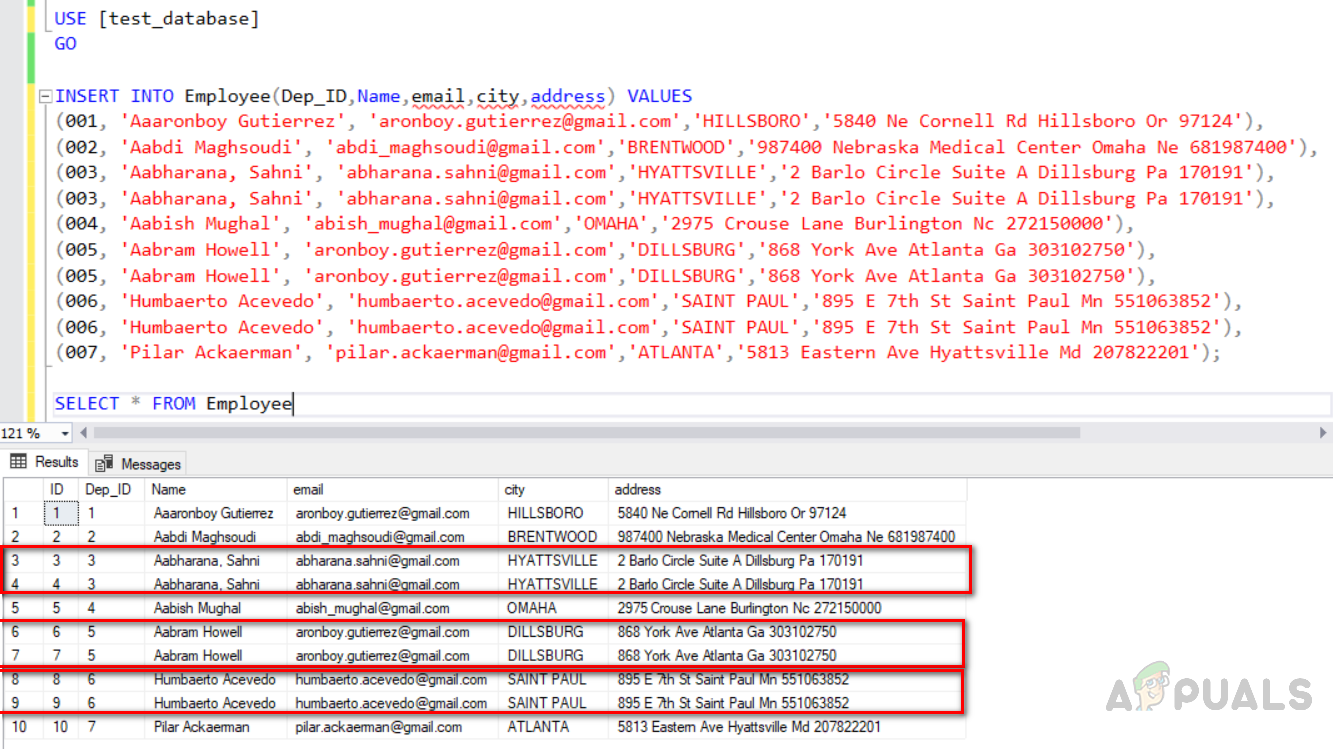
Fügen Sie nun Daten in die Tabelle ein. Wir werden auch doppelte Zeilen einfügen. Die “Dep_ID” 003.005 und 006 sind doppelte Zeilen mit ähnlichen Daten in allen Feldern mit Ausnahme der Identitätsspalte mit einem eindeutigen Schlüsselindex. Führen Sie den unten angegebenen Code aus.
USE [test_database] GO INSERT INTO Employee(Dep_ID,Name,email,city,address) VALUES (001, 'Aaaronboy Gutierrez', 'aronboy.gutierrez@gmail.com','HILLSBORO','5840 Ne Cornell Rd Hillsboro Or 97124'), (002, 'Aabdi Maghsoudi', 'abdi_maghsoudi@gmail.com','BRENTWOOD','987400 Nebraska Medical Center Omaha Ne 681987400'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (004, 'Aabish Mughal', 'abish_mughal@gmail.com','OMAHA','2975 Crouse Lane Burlington Nc 272150000'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (007, 'Pilar Ackaerman', 'pilar.ackaerman@gmail.com','ATLANTA','5813 Eastern Ave Hyattsville Md 207822201'); SELECT * FROM Employee
Die Ausgabe wird wie folgt sein.
Suchen Sie nun die Anzahl der Zeilen in der Tabelle, indem Sie den folgenden Code ausführen. Die Zählung
SELECT Dep_ID,Name,email,city,address, COUNT(*) AS duplicate_rows_count FROM Employee GROUP BY Dep_ID,Name,email,city,address
Funktion zählt keine Zeilen.
Diese Abbildung zeigt doppelte Zeilen mit row_no größer als 1
Unsere Aufgabe ist es, die Eindeutigkeit durch Entfernen von Duplikaten für die doppelten Spalten zu erzwingen. Es ist etwas einfacher, doppelte Werte mit einem eindeutigen Index aus der Tabelle zu entfernen, als die Zeilen ohne einen Index aus einer Tabelle zu entfernen. Im Folgenden sind zwei Methoden angegeben, um dies zu erreichen. Mit der ersten Methode können Sie mit der Funktion “row_number ()” doppelte Zeilen aus der Tabelle erstellen, während mit der zweiten Methode die Funktion “NOT IN” verwendet wird. Diese beiden Methoden haben ihre eigenen Kosten, die später erörtert werden.
select * from (SELECT Dep_ID,Name,email,city,address, ROW_NUMBER() OVER ( PARTITION BY Dep_ID,Name,email,city,address ORDER BY Dep_ID,Name,email,city,address ) row_no FROM test_database.dbo.Employee) x where row_no>1
Methode 1: Auswählen doppelter Datensätze mit der Funktion „ROW_NUMBER ()“
SELECT * FROM test_database.dbo.Employee WHERE ID NOT IN (SELECT MAX(ID) FROM test_database.dbo.Employee GROUP BY Dep_ID,Name,email,city,address)
Methode 2: Auswählen doppelter Datensätze mit der Funktion „NOT IN ()“
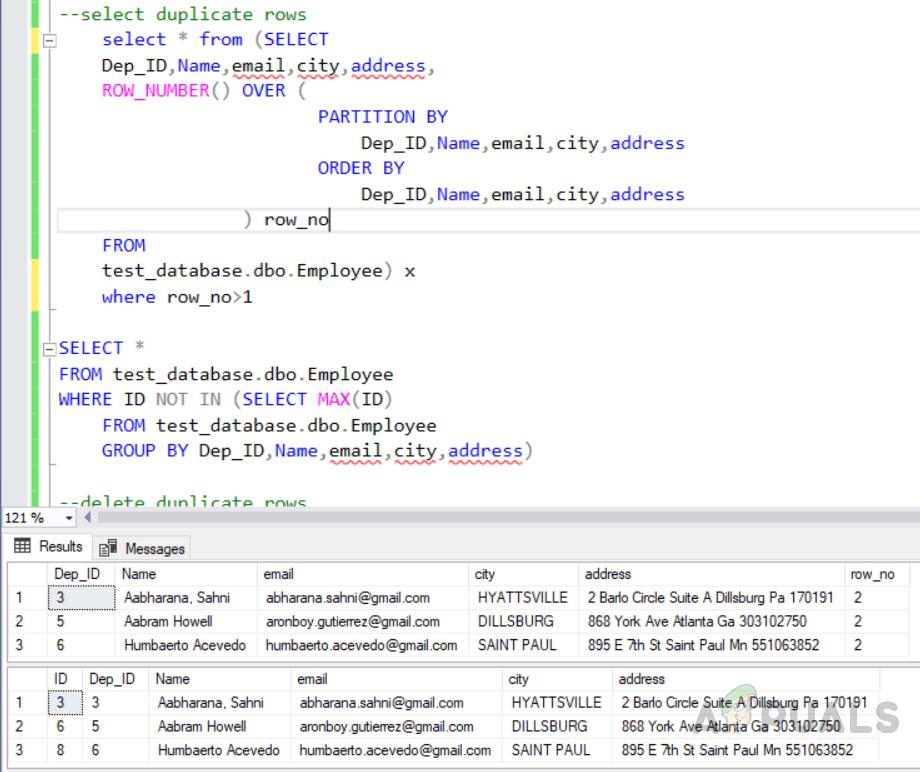
Auswählen doppelter Zeilen aus der Tabelle mit dem Namen “Mitarbeiter” mit Methode 1 bzw. 2
Jetzt löschen wir die oben ausgewählten doppelten Zeilen mit “CTE” unter Verwendung des folgenden Codes. Der folgende Code wählt doppelte Zeilen aus, die mit der Funktion „ROW_NUMBER ()“ gelöscht werden sollen.
WITH cte_delete AS (
SELECT
Dep_ID,Name,email,city,address,
ROW_NUMBER() OVER (
PARTITION BY
Dep_ID,Name,email,city,address
ORDER BY
Dep_ID,Name,email,city,address
) row_no
FROM
test_database.dbo.Employee
)
DELETE FROM cte_delete WHERE row_no > 1;Methode 1: Löschen doppelter Datensätze mit der Funktion „ROW_NUMBER ()“
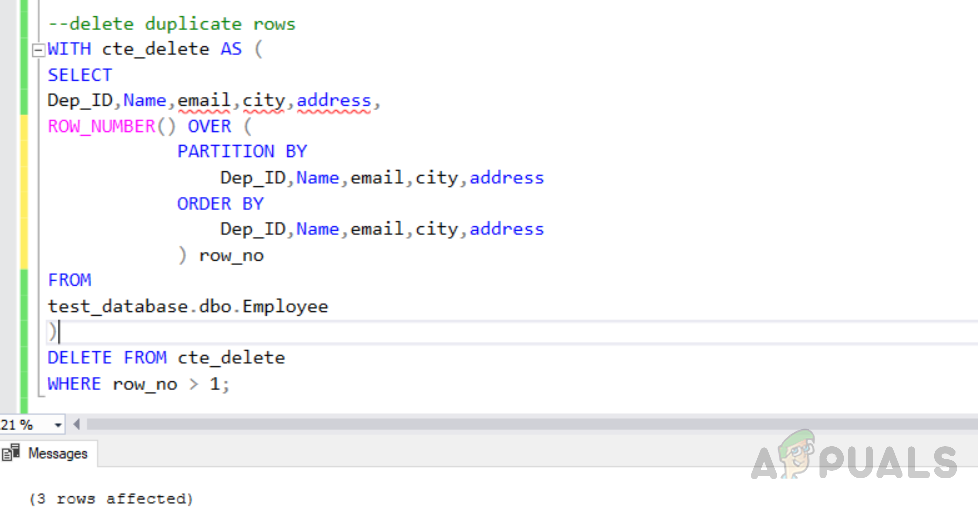
Löschen doppelter Datensätze aus der indizierten Tabelle mit der Funktion „ROW_NUMBER ()“
Methode 2: Löschen doppelter Datensätze mit der Funktion „NOT IN ()“
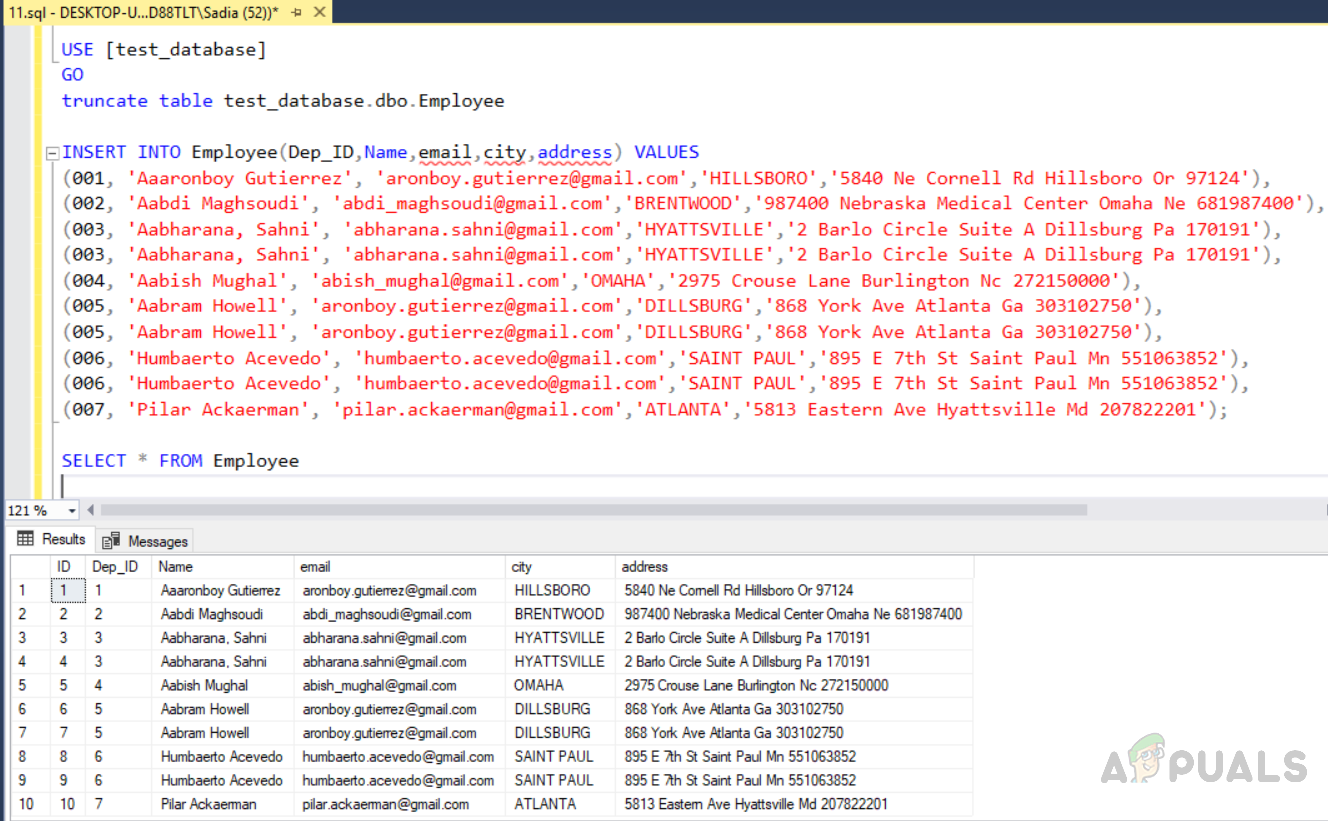
USE [test_database] GO truncate table test_database.dbo.Employee INSERT INTO Employee(Dep_ID,Name,email,city,address) VALUES (001, 'Aaaronboy Gutierrez', 'aronboy.gutierrez@gmail.com','HILLSBORO','5840 Ne Cornell Rd Hillsboro Or 97124'), (002, 'Aabdi Maghsoudi', 'abdi_maghsoudi@gmail.com','BRENTWOOD','987400 Nebraska Medical Center Omaha Ne 681987400'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (004, 'Aabish Mughal', 'abish_mughal@gmail.com','OMAHA','2975 Crouse Lane Burlington Nc 272150000'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (007, 'Pilar Ackaerman', 'pilar.ackaerman@gmail.com','ATLANTA','5813 Eastern Ave Hyattsville Md 207822201'); SELECT * FROM Employee
Um nun eine andere Methode zu testen, müssen wir die Tabelle abschneiden, wodurch alle Zeilen aus der Tabelle entfernt werden. Der Befehl insert fügt dann Werte zur Tabelle hinzu. Führen Sie jetzt den folgenden Code aus.
Einfügen von Daten in die Tabelle mit dem Namen “Mitarbeiter” und Abrufen von Daten aus derselben Tabelle.
Delete FROM test_database.dbo.Employee WHERE ID NOT IN (SELECT MAX(ID) FROM test_database.dbo.Employee GROUP BY Dep_ID,Name,email,city,address)
Führen Sie den unten angegebenen Code aus, um alle doppelten Zeilen aus der Tabelle “Mitarbeiter” zu löschen.
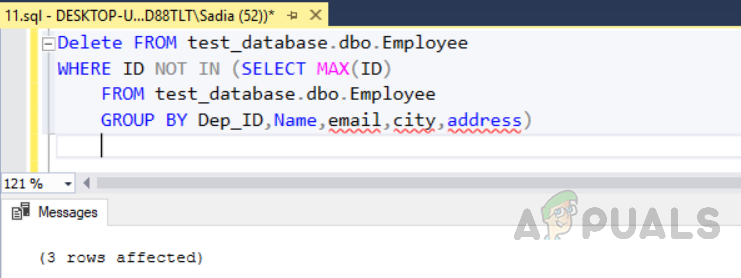
Löschen Sie alle doppelten Zeilen aus der indizierten Tabelle mit dem Namen „Mitarbeiter
Ausführungsplan und Abfragekosten für das Löschen doppelter Zeilen aus der indizierten Tabelle:
Jetzt müssen wir prüfen, welche Methode kostengünstig ist und weniger Ressourcen benötigt. Wählen Sie den Code aus und klicken Sie auf den Ausführungsplan. Der folgende Bildschirm zeigt alle ausgeführten Pläne zusammen mit dem Kostenprozentsatz.
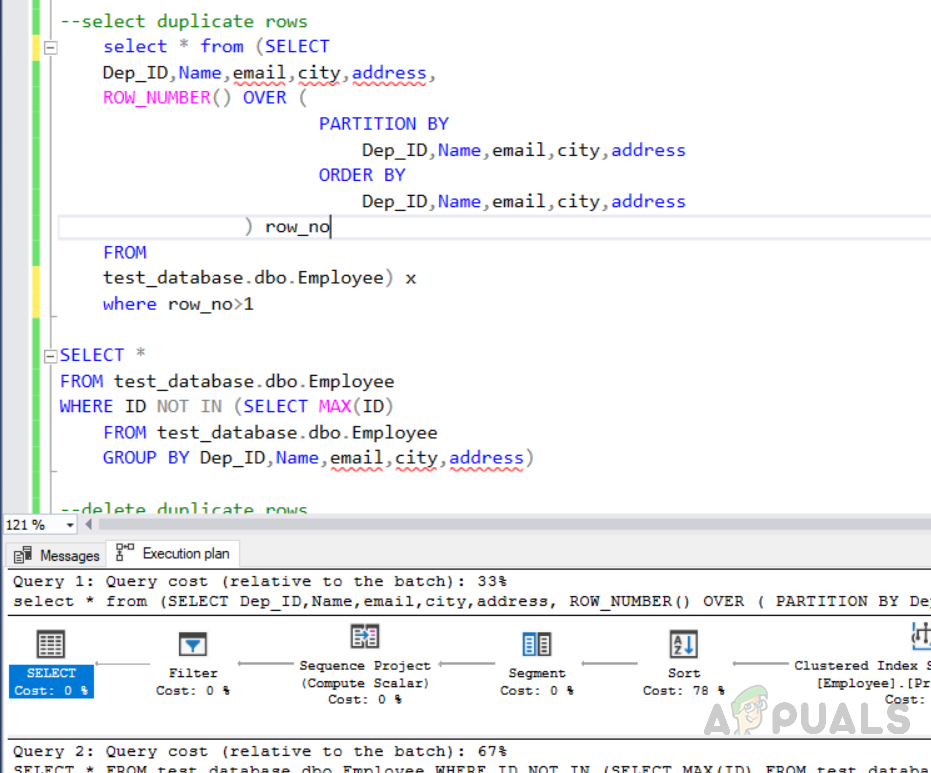
Methode 1 hat 33% Kosten und Methode 2 hat 67% Kosten, was zeigt, dass Methode 1 kostengünstiger ist.
Entfernen von Duplikaten aus einer SQL Server-Tabelle ohne eindeutigen Index:
Es ist etwas schwieriger, doppelte Zeilen oder Tabellen ohne einen eindeutigen Index zu entfernen. In diesem Szenario hilft uns die Verwendung eines allgemeinen Tabellenausdrucks (CTE) und der Funktion ROW NUMBER () beim Entfernen der doppelten Datensätze. Um Duplikate ohne eindeutigen Index aus der Tabelle zu entfernen, müssen eindeutige Zeilenbezeichner generiert werden.
USE [test_database] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Employee_with_out_index]( [Dep_ID] [int] NULL, [Name] [varchar](200) NULL, [email] [varchar](250) NULL, [city] [varchar](250) NULL, [address] [varchar](500) NULL, ) GO
Führen Sie den folgenden Code aus, um die Tabelle ohne eindeutigen Index zu erstellen.
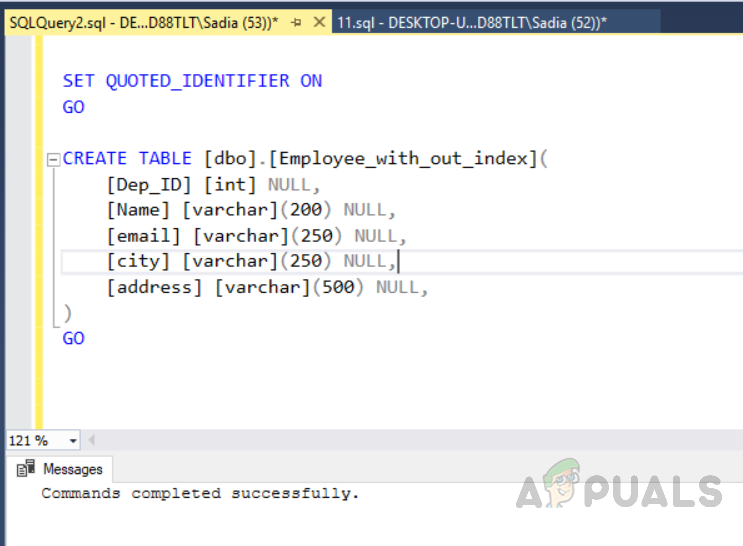
Erstellen der Tabelle mit dem Namen “Employee_with_out_index” ohne eindeutigen Index
USE [test_database] GO INSERT INTO Employee_with_out_index(Dep_ID,Name,email,city,address) VALUES (001, 'Aaaronboy Gutierrez', 'aronboy.gutierrez@gmail.com','HILLSBORO','5840 Ne Cornell Rd Hillsboro Or 97124'), (002, 'Aabdi Maghsoudi', 'abdi_maghsoudi@gmail.com','BRENTWOOD','987400 Nebraska Medical Center Omaha Ne 681987400'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (004, 'Aabish Mughal', 'abish_mughal@gmail.com','OMAHA','2975 Crouse Lane Burlington Nc 272150000'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (007, 'Pilar Ackaerman', 'pilar.ackaerman@gmail.com','ATLANTA','5813 Eastern Ave Hyattsville Md 207822201'); SELECT * FROM Employee_with_out_index
Fügen Sie nun Datensätze in die erstellte Tabelle mit dem Namen “Employee_with_out_index” ein, indem Sie den folgenden Code ausführen.
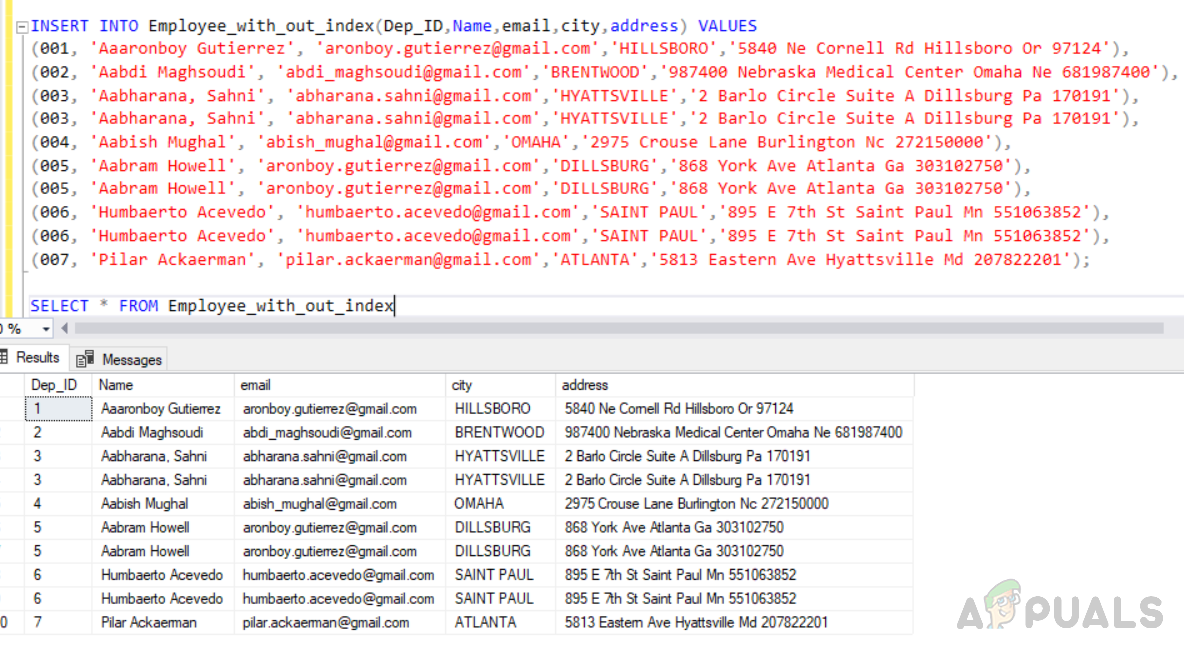
Einfügen von Daten in die Tabelle mit einem Out-Index namens “Employee_with_out_index”
Methode 1: Löschen doppelter Zeilen aus einer Tabelle mit der Funktion „ROW_NUMBER ()“ und JOINS.
WITH temp_tablr_with_row_ids AS ( SELECT ROW_NUMBER() OVER (ORDER BY Dep_ID,Name,email,city,address) AS row_no, Dep_ID,Name,email,city,address FROM test_database.dbo.Employee_with_out_index ) DELETE a FROM temp_tablr_with_row_ids a WHERE row_no < (SELECT MAX(row_no) FROM temp_tablr_with_row_ids i WHERE a.Dep_ID=i.Dep_ID and a.Name=i.Name and a.email=i.email and a.city=i.city and a.address=i.address GROUP BY Dep_ID,Name,email,city,address)
Führen Sie den folgenden Code aus, der die Funktion ROW_NUMBER () und JOIN verwendet, um doppelte Zeilen ohne Index aus der Tabelle zu entfernen. Die IT erstellt zunächst eine eindeutige Identität, um allen Zeilen row_no zuzuweisen und nur eine Zeile zu entfernen, um doppelte zu entfernen.
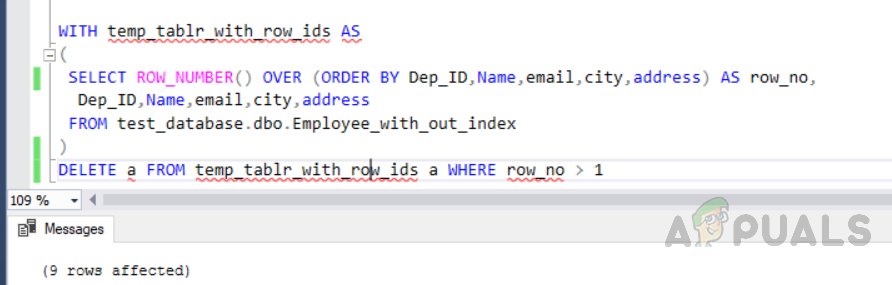
Löschen doppelter Zeilen aus einer Tabelle ohne Index mit der Funktion „ROW_NUMBER ()“ und JOINS
Methode 2: Löschen doppelter Zeilen aus einer Tabelle mit der Funktion „ROW_NUMBER ()“ und PARTITION BY.
truncate table Employee_with_out_index INSERT INTO Employee_with_out_index(Dep_ID,Name,email,city,address) VALUES (001, 'Aaaronboy Gutierrez', 'aronboy.gutierrez@gmail.com','HILLSBORO','5840 Ne Cornell Rd Hillsboro Or 97124'), (002, 'Aabdi Maghsoudi', 'abdi_maghsoudi@gmail.com','BRENTWOOD','987400 Nebraska Medical Center Omaha Ne 681987400'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (003, 'Aabharana, Sahni', 'abharana.sahni@gmail.com','HYATTSVILLE','2 Barlo Circle Suite A Dillsburg Pa 170191'), (004, 'Aabish Mughal', 'abish_mughal@gmail.com','OMAHA','2975 Crouse Lane Burlington Nc 272150000'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (005, 'Aabram Howell', 'aronboy.gutierrez@gmail.com','DILLSBURG','868 York Ave Atlanta Ga 303102750'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (006, 'Humbaerto Acevedo', 'humbaerto.acevedo@gmail.com','SAINT PAUL','895 E 7th St Saint Paul Mn 551063852'), (007, 'Pilar Ackaerman', 'pilar.ackaerman@gmail.com','ATLANTA','5813 Eastern Ave Hyattsville Md 207822201');
Bei dieser Methode verwenden wir jetzt die Funktion ROW_NUMBER zusammen mit der Klausel partition by, um allen Zeilen row_no zuzuweisen und dann doppelte zu löschen. Zunächst müssen wir dieselbe Tabelle abschneiden, die wir zuvor erstellt haben, damit alle Daten aus der Tabelle gelöscht werden. Fügen Sie dann Datensätze in die Tabelle ein, einschließlich der doppelten Datensätze. Bei der dritten Abfrage werden doppelte Zeilen aus der Tabelle "Employee_with_out_index" gelöscht.
; WITH temp_tablr_with_row_ids AS ( SELECT ROW_NUMBER() OVER (PARTITION BY Dep_ID,Name,email,city,address ORDER BY Dep_ID,Name,email,city,address) AS row_no, Dep_ID,Name,email,city,address FROM Employee_with_out_index )
Auswählen doppelter Datensätze in der temporären Tabelle
DELETE a FROM temp_tablr_with_row_ids a WHERE row_no > 1
Löschen doppelter Datensätze aus der temporären Tabelle
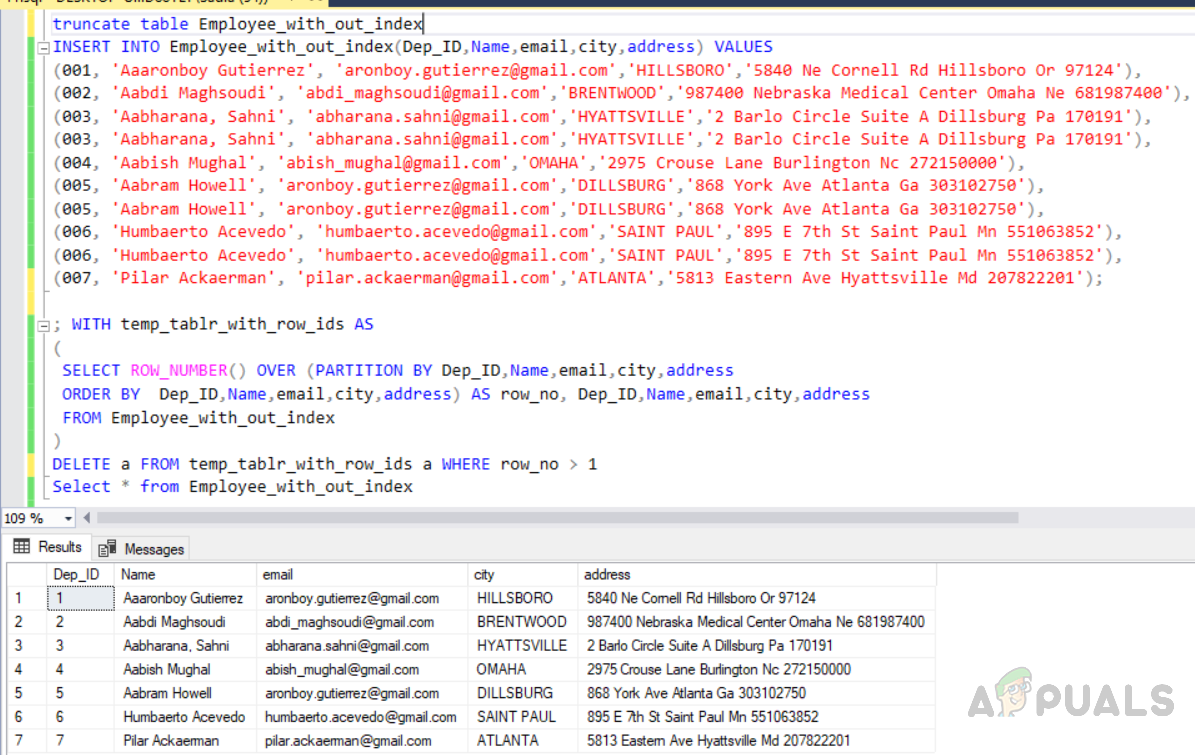
Abschneiden, Einfügen, Löschen doppelter Zeilen aus einer Tabelle ohne Index und Auswählen der resultierenden Datensätze.
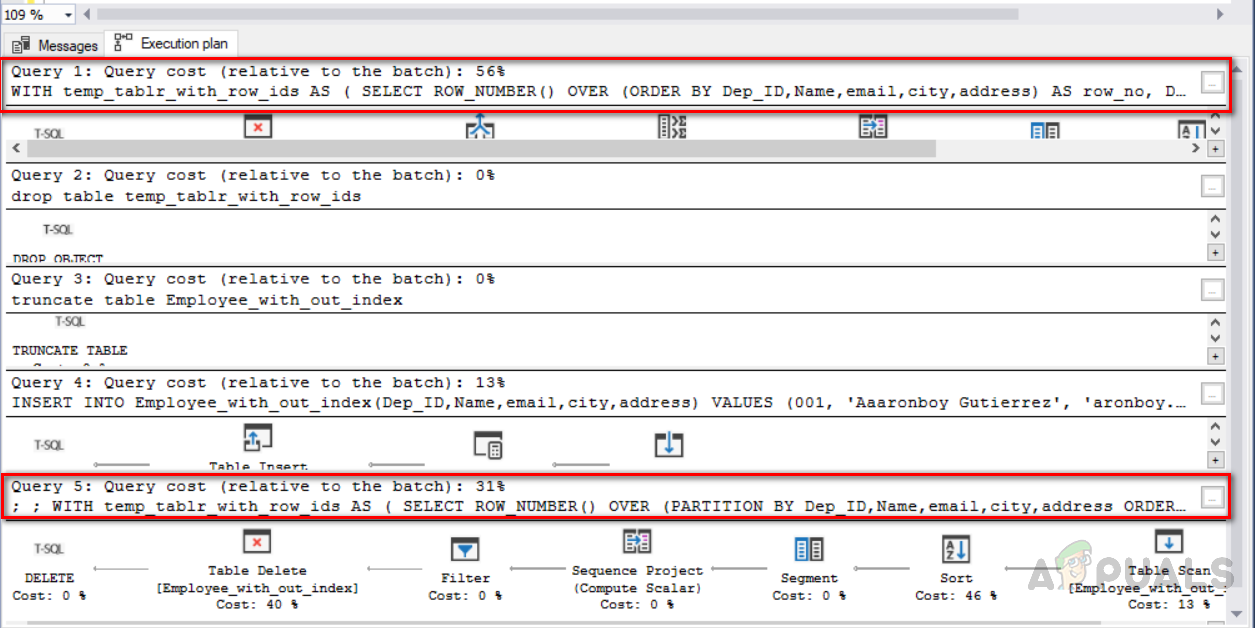
Die erste Abfrage, die die Klausel "ROW_NUMBER ()" und JOIN verwendet, hat 56% Ausführungskosten, während die zweite Abfrage "ROW_NUMBER ()" und "PARTITION BY" 31% Kosten hat. Die zweite Methode ist also optimierter

![[FIX] Fehler beim Festlegen von Eigenschaften beim Anbieter](https://okidk.de/wp-content/uploads/2021/07/error-setting-traits-on-provider.jpg)
